转自:https://blog.csdn.net/u014381464/article/details/81101551
规范化:
- 针对数据库
规范化把关系满足的规范要求分为几级,满足要求最低的是第一范式(1NF),再来是第二范式、第三范式、BC范式和4NF、5NF等等,范数的等级越高,满足的约束集条件越严格。
- 针对数据
数据的规范化包括归一化标准化正则化,是一个统称(也有人把标准化作为统称)。
数据规范化是数据挖掘中的数据变换的一种方式,数据变换将数据变换或统一成适合于数据挖掘的形式,将被挖掘对象的属性数据按比例缩放,使其落入一个小的特定区间内,如[-1, 1]或[0, 1]
对属性值进行规范化常用于涉及神经网络和距离度量的分类算法和聚类算法当中。比如使用神经网络后向传播算法进行分类挖掘时,对训练元组中度量每个属性的输入值进行规范化有利于加快学习阶段的速度。对于基于距离度量相异度的方法,数据归一化能够让所有的属性具有相同的权值。
数据规范化的常用方法有三种:最小最大值规范化,z-score标准化和按小数定标规范化
标准化(standardization):
数据标准化是将数据按比例缩放,使其落入到一个小的区间内,标准化后的数据可正可负,但是一般绝对值不会太大,一般是z-score标准化方法:减去期望后除以标准差。
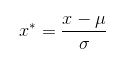
特点:
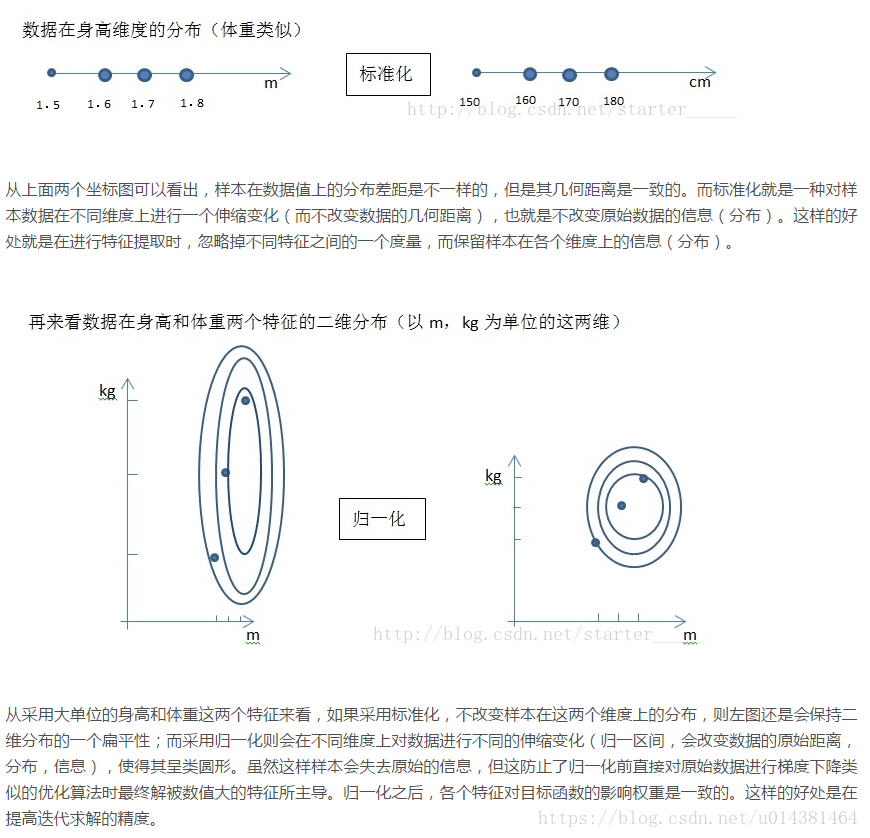
对不同特征维度的伸缩变换的目的是使其不同度量之间的特征具有可比性,同时不改变原始数据的分布。
好处:
不改变原始数据的分布,保持各个特征维度对目标函数的影响权重
对目标函数的影响体现在几何分布上在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景归一化(normalization):
把数值放缩到0到1的小区间中(归到数字信号处理范畴之内),一般方法是最小最大规范的方法:min-max normalization
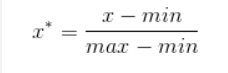
上面min-max normalization是线性归一化,还有非线性归一化,通过一些数学函数,将原始值进行映射。该方法包括log、指数、反正切等。需要根据数据分布的情况,决定非线性函数的曲线。
log函数:x = lg(x)/lg(max);反正切函数:x = atan(x)*2/pi
应用:
1.无量纲化
例如房子数量和收入,从业务层知道这两者的重要性一样,所以把它们全部归一化,这是从业务层面上作的处理。2.避免数值问题
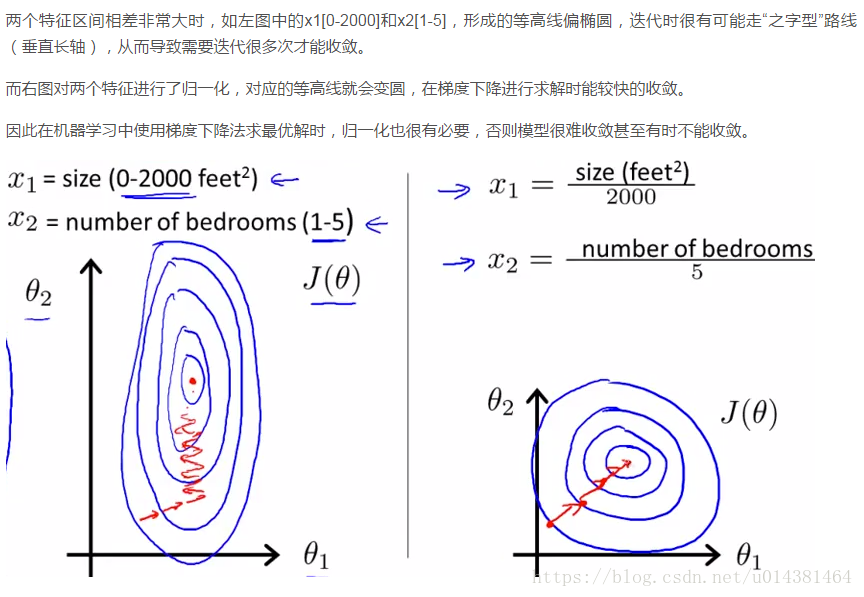
不同的数据在不同列数据的数量级相差过大的话,计算起来大数的变化会掩盖掉小数的变化。3.一些模型求解的需要
例如梯度下降法,如果不归一化,当学习率较大时,求解过程会呈之字形下降。学习率较小,则会产生直角形路线,不管怎么样,都不会是好路线(路线解释看西面归一化和标准化的对比)。解释神经网络梯度下降的文章。4.时间序列
进行log分析时,会将原本绝对化的时间序列归一化到某个基准时刻,形成相对时间序列,方便排查。5.收敛速度
加快求解过程中参数的收敛速度。特点:
对不同特征维度进行伸缩变换
改变原始数据的分布,使得各个特征维度对目标函数的影响权重归于一致(使得扁平分布的数据伸缩变换成类圆形)对目标函数的影响体现在数值上把有量纲表达式变为无量纲表达式归一化可以消除量纲对最终结果的影响,使不同变量具有可比性。比如两个人体重差10KG,身高差0.02M,在衡量两个人的差别时体重的差距会把身高的差距完全掩盖,归一化之后就不会有这样的问题。好处:
提高迭代求解的收敛速度
提高迭代求解的精度缺点:最大值与最小值非常容易受异常点影响
鲁棒性较差,只适合传统精确小数据场景标准化vs归一化
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,标准化(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
正则化(regularization):
在求解最优化问题中,调节拟合程度的参数一般称为正则项,越大表明欠拟合,越小表明过拟合
为了解决过拟合问题,通常有两种方法,第一是减小样本的特征(即维度),第二是正则化(又称为惩罚penalty)
正则化的一般形式是在整个平均损失函数的最后增加一个正则项(L2范数正则化,也有其他形式的正则化,作用不同)
正则项越大表明惩罚力度越大,等于0表示不做惩罚。
正则项越小,惩罚力度越小,极端为正则项为0,则会造成过拟合问题;正则化越大,惩罚力度越大,则容易出现欠拟合问题。